Using Solr and TikaOCR to search text inside an image

Tesseract is probably the most accurate open source OCR engine available and with Apache Tika 1.7 you can now use the awesome Tesseract OCR parser within Tika!
Solr 5.x has support for Tika 1.7 (See this) . I wanted to try this in Solr 5.2 so I configured this on my machine, Below are the steps required to make TikaOCR work with Solr 5.2.
Tika OCR works OOTB in Solr we just need to install Tesseract and set class path accordingly. You can download Tesseract from here. This is native tool and it does the actual work. I have used version 3.02.02 in my case.
Next step is to enable extract request handler in solrconfig.xml.
<requestHandler name="/update/extract" startup="lazy" class="solr.extraction.ExtractingRequestHandler" >
<lst name="defaults">
<str name="lowernames">true</str>
<str name="uprefix">ignored_</str>
<str name="captureAttr">true</str>
</lst>
</requestHandler>
We will use the below image for OCR.
Now from Solr admin we can upload image file to Extracting request handler with following parameters. literal.id=d1&uprefix=attr_&fmap.content=attr_content&commit=true
Sample Url is : http://{$solr_host}:{$solr_port}/solr/techproducts/update/extract?wt=json&literal.id=d1&uprefix=attr_&fmap.content=attr_content&commit=true
See below image for more information,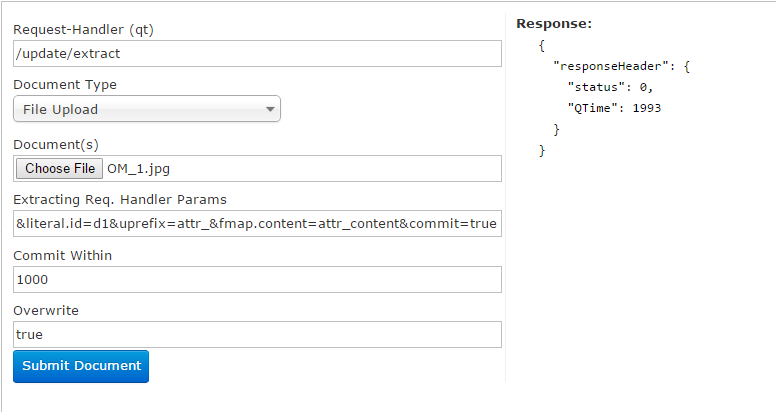
Click Submit, If everything goes well this image will be indexed with id “d1?. we can query Solr for this id to see what Tika has extracted from image. it has extracted many features from uploaded image.
{
"responseHeader":{
"status":0,
"QTims":{
"q":"id:d1",
"indene":1,
"paramt":"true",
"fl":"*",
"wt":"json"
}
},
"response":{
"numFound":1,
"start":0,
"docs":[
{
"id":"d1",
"attr_stream_size":[
"55422"
],
"attr_x_parsed_by":[
"org.apache.tika.parser.DefaultParser",
"org.apache.tika.parser.ocr.TesseractOCRParser",
"org.apache.tika.parser.jpeg.JpegParser"
],
"attr_stream_content_type":[
"image/jpeg"
],
"attr_resolution_units":[
"inch"
],
"attr_stream_source_info":[
"the-file"
],
"attr_compression_type":[
"Progressive, Huffman"
],
"attr_data_precision":[
"8 bits"
],
"attr_number_of_components":[
"3"
],
"attr_tiff_imagelength":[
"286"
],
"attr_component_2":[
"Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert"
],
"attr_component_1":[
"Y component: Quantization table 0, Sampling factors 2 horiz/2 vert"
],
"attr_image_height":[
"286 pixels"
],
"attr_x_resolution":[
"72 dots"
],
"attr_image_width":[
"690 pixels"
],
"attr_stream_name":[
"OM_1.jpg"
],
"attr_component_3":[
"Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert"
],
"attr_tiff_bitspersample":[
"8"
],
"attr_tiff_imagewidth":[
"690"
],
"content_type":[
"image/jpeg"
],
"attr_y_resolution":[
"72 dots"
],
"attr_content":[
" \n \n \n \n \n \n \n \n \n \n \n ‘ '\"I“ \" \"' ./\nlrast. Shortly before the classes started I was visiting a.\ncertain public school, a school set in a typically English\ncountryside, which on the June clay of my visit was wonder-\nfully beauliful. The Head Master—-no less typical than his\nschool and the country-side—pointed out the charms of\nboth, and his pride came out in the ?nal remark which he made\nbeforehe left me. He explained that he had a class to take\nin'I'heocritus. Then (with a. buoyant gesture); “ Can you\n\n, conceive anything more delightful than a class in Theocritus,\n\non such a day and in such a place?\"\n\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n "
],
"_version_":1506952201156689920
}
]
}
}
Here in above response if we see “attr_content” which is the actual field where OCR output is stored.
“attr_content”:[
” \n \n \n \n \n \n \n \n \n \n \n ‘ ‘\”I“ \” \”‘ ./\nlrast. Shortly before the classes started I was visiting a.\ncertain public school, a school set in a typically English\ncountryside, which on the June clay of my visit was wonder-\nfully beauliful. The Head Master—-no less typical than his\nschool and the country-side—pointed out the charms of\nboth, and his pride came out in the ?nal remark which he made\nbeforehe left me. He explained that he had a class to take\nin’I’heocritus. Then (with a. buoyant gesture); “ Can you\n\n, conceive anything more delightful than a class in Theocritus,\n\non such a day and in such a place?\”\n\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n ”
]
These results are very much accurate. If in case results are not so accurate then we can use some context-based or linguistic error correction algorithm to clean/correct text.
Write a comment
- vikas shinde October 18, 2019, 11:31 amHow to configure ocr in solr? Configuration details are missing from current document.reply
- Brian Hagan September 17, 2015, 4:54 amThanks Vijay, I used this post successfully. The tricky part for me was building leptonica on Centos due to pathing and the required dependencies.reply
Subscribe To Our Newsletter
Join our mailing list to receive the latest blogs and updates.