High Speed Ingestion into Solr with Custom Talend Component Developed by T/DG

In this blog I will explain how to use High Speed Talend-Solr Ingestion components, released by T/DG as open source, for ingesting documents into Solr and its benefit.
T/DG released 3 custom Talend components, which can be freely download from Talend Exchange – Marketplace.
Before explaining how to use Talend ETL tool to ingest data into Solr, we will see various options available for ingesting data into Solr and advantage of using Talend over other options.
In real life Solr is used for searching millions of documents, so there is a challenge of indexing millions of documents into Solr from different data sources. The raw content needs to be transformed into document format supported by Solr and this transformation may involve complex processing logic. Also to increase indexing speed, there is a necessity to do processing in batch and in parallel.
Using Solr out of box tools for data ingestion:
Solr provides out of box tools like DIH handler, SolrJ client API for indexing documents, but again these solutions have their own drawbacks.
With DIH handler, as all the data processing during indexing is done within Solr JVM, using DIH would load Solr server JVM heavily.
With SolrJ, we can process data outside Solr JVM, but again if you want to change processing logic, you have to make changes in java code in the client application, which is time consuming.
Using Talend ETL tool, with T/DG released High Speed Talend-Solr Ingestion component for data ingestion:
Using Talend tool, with T/DG released High Speed Talend-Solr Ingestion component, has many advantages over using DIH or SolrJ tools.
- Talend which is and ETL tool, provides greater flexibility at the data integration layer. With Talend ETL tool you can read data from any database or from any file format.
- The processing on raw data to transform into Solr document format, is done outside Solr JVM. So there will not be additional load on Solr JVM due to processing logic.
- Complex workflows for transforming and processing data can be defined easily by adding talend components in the job and connecting them.
- Data can be processed in parallel and in batch to improve processing speed.
- The processing workflow can be easily changed in talend, in case there is a need to change processing logic.
- T/DG released custom talend components for Solr are freely available.
- As this T/DG component is based on latest SolrJ 5.1 API, you will get high ingestion speed. The speed of ingestion with T/DG component, is 2.5 times faster than the speed of ingestion with old Talend component available for Solr ingestion.
Now I will show how to use Talend ETL tool and T/DG High Speed Talend-Solr Ingestion component, for data ingestion into Solr. Here are the steps to follow:
Step 1: Download Talend components released by T/DG from Talend exchange site which are freely available
On Talend Exchange site ( https://exchange.talend.com/) , if you search for Solr components you will find 3 components released by TDG, as show in the below picture.
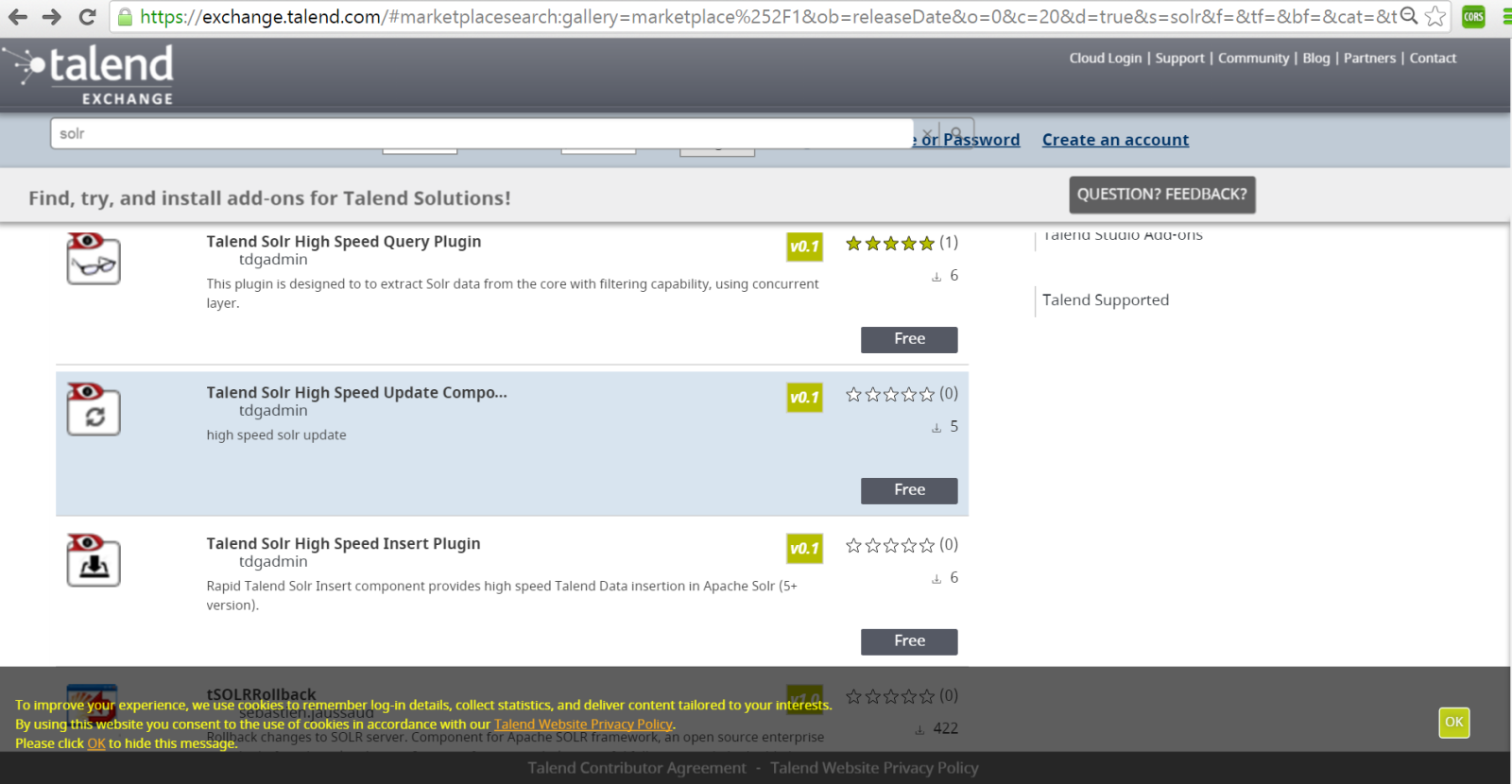
Step 2: Extract downloaded zip files and import components into Talend. After importing you will see these components listed in the pallet as shown below:
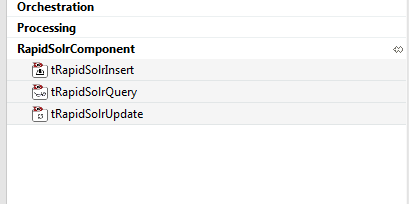
Fig. Solr components in pallet window
Step 3: I have used Wikipedia dataset for indexing, which is available freely. This database dump can be downloaded from: https://dumps.wikimedia.org/enwiki/20160204/enwiki-20160204-pages-articles-multistream.xml.bz2
The downloaded dump is in xml format. Here is the structure of xml file.
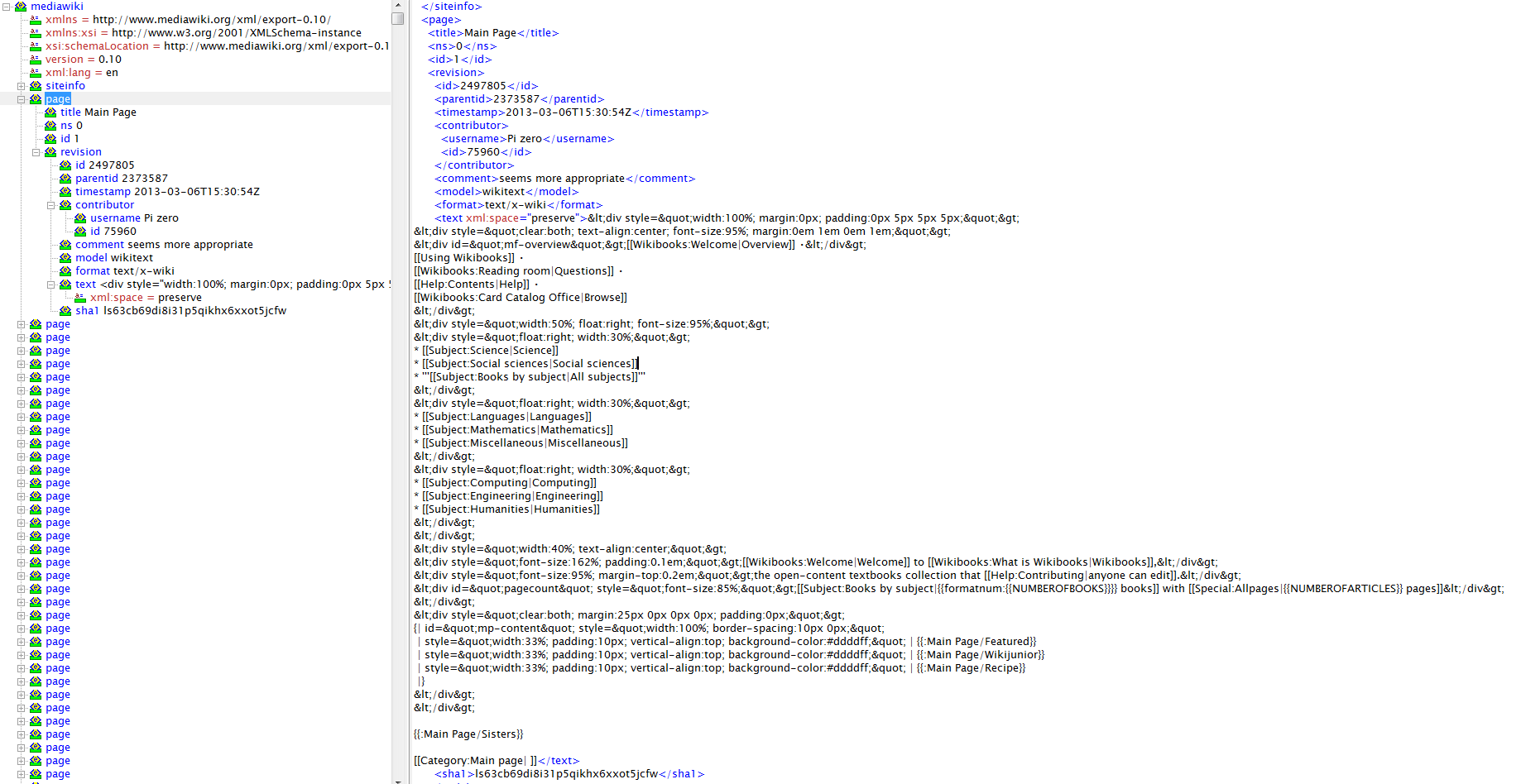
Fig. XML file structure
Step 4: Create new Solr core and define Solr schema as show below
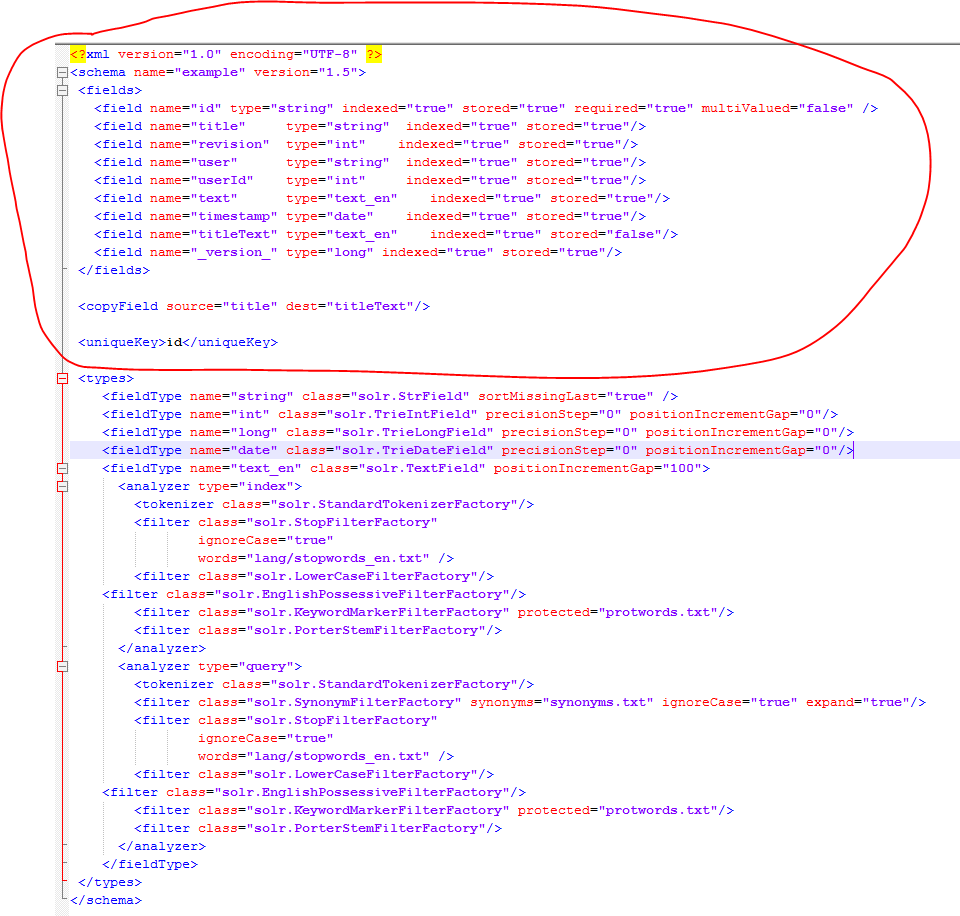
Fig. Solr Schema
Step 5. Create a new talend job and add following 2 components in the job
- tFileInputMSXML component - for parsing Wikipedia xml
- tRapidSolrInsert component – for indexing new documents into solr.
tRapidSolrInsert component is based on latest SolJ 5.1 API, so you will get high indexing speed, as ConcurrentUpdateSolrClient available in SolrJ 5.1 API, allows to specify number of concurrent threads and batch Size.
After adding above 2 components in the job, connect these components as shown below.
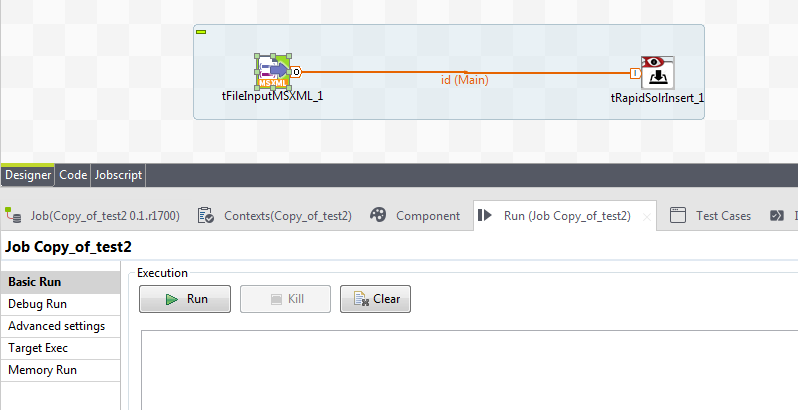
Fig. Talend Job connection
Step 6. Define mapping schema as shown below.
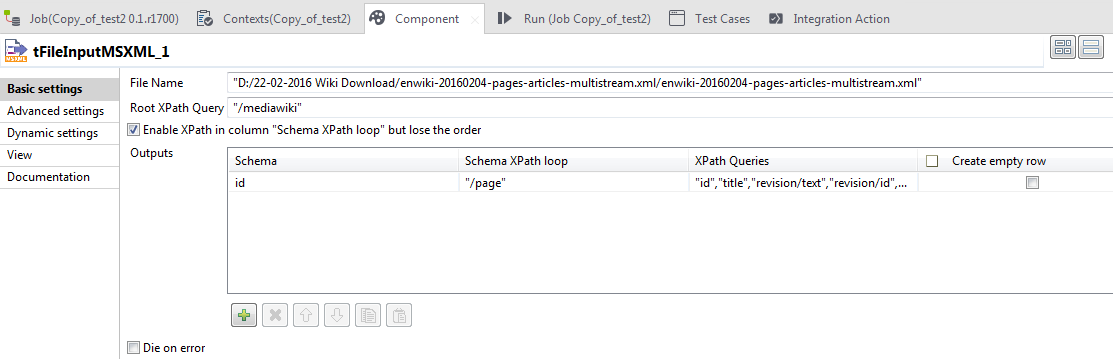
Fig. tFileInputMSXML Property window
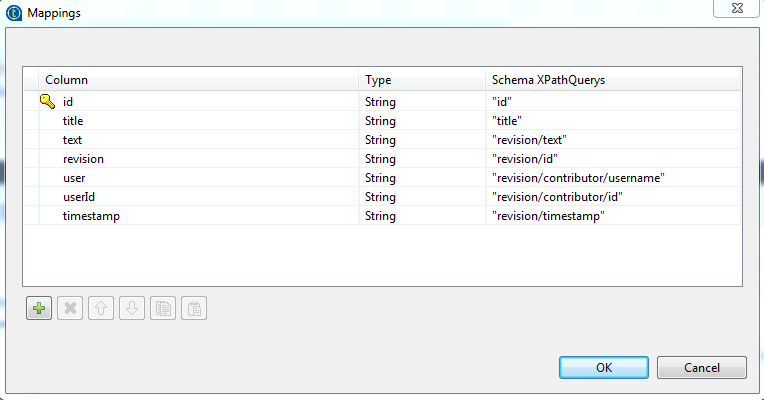
Fig. XML schema
Step 7. Specify Solr core url, number of concurrent threads and batch size as shown below.
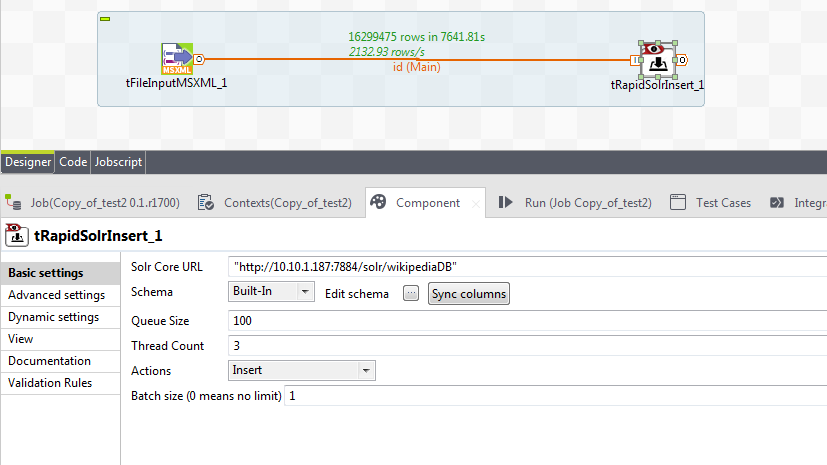
Fig. tRapidSolrInsert property window
Step 8. Execute Job.
After the job is finished, as show in the picture below more than 16 million documents are indexed into Solr in 7641 seconds at the speed of 2132 documents per second.
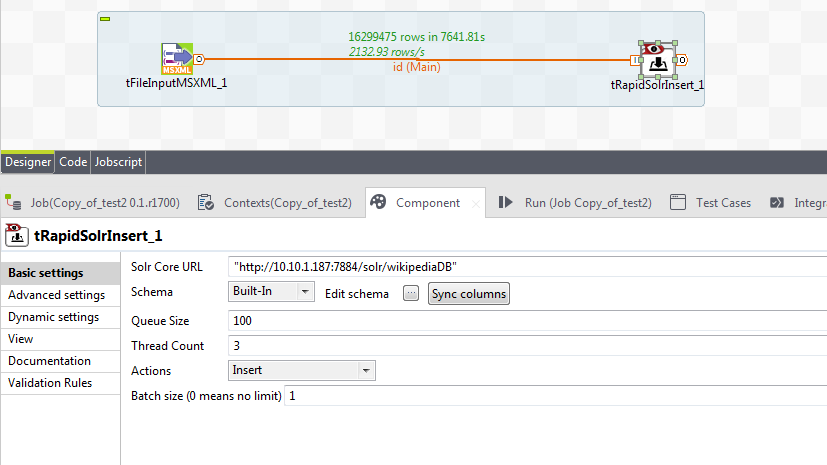
Fig. Processed number of documents with time
Step 9. On solr admin console you can see 16299475 (More than 16 million) number of documents indexed
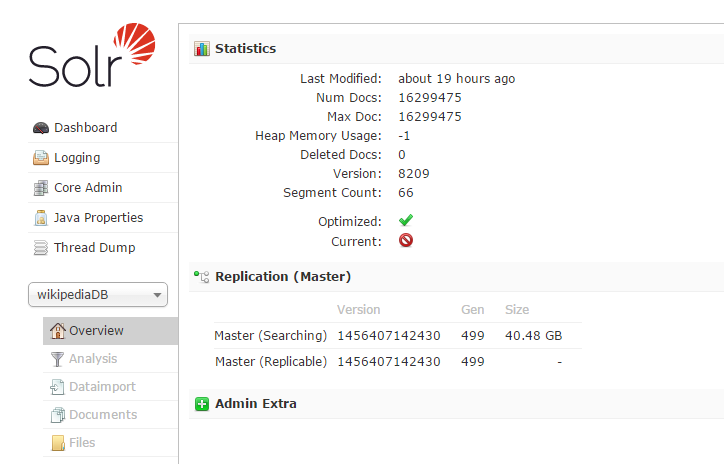
Fig. Number of documents indexed on Solr end
Step 10. Querying Solr will show you indexed document result as show below.
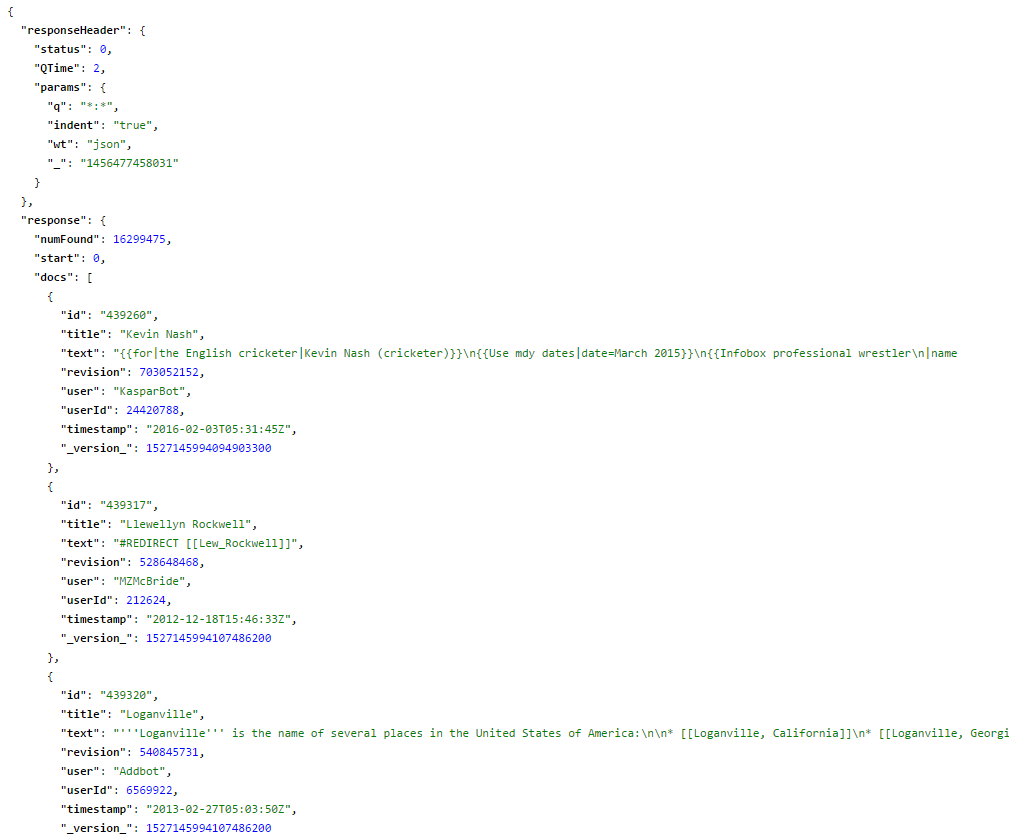
Fig. Documents on Solr after querying
Conclusion: Using Talend tool with T/DG released Talend components for Solr, has many advantages.
1. High ingestion speed can be achieved as T/DG Talend components for Solr is using latest SolrJ 5.1 API.
2. In Talend ETL, data can be read form any input source like databases, files etc.
3. Complex processing logic can be defined easily in Talend and high processing speed can be achieved through parallel and batch processing of data.
4. Most important is data is processed outside Solr JVM, hence less load on Solr JVM.
Write a comment
Subscribe To Our Newsletter
Join our mailing list to receive the latest blogs and updates.