Evaluating Search Engine Relevance with Precision Testing
Evaluating search engines
For any information retrieval system, a major challenge is to provide the most relevant and meaningful search results to the user. It should not return irrelevant results in the top results, although it should be able to return as many relevant results as possible.
Classic information retrieval metrics to evaluate search engines are Precision and Recall. These metrics are widely used in information retrieval systems, which return some set of best results for a query out of many possible results. In this article, we will discuss relevancy, its meaning, importance and underlying processes to control and improve in an evolving environment.
Precision:
Within the context of information retrieval we define precision as the fraction of retrieved documents that are relevant to the query. Precision takes all retrieved documents into account and asks how close they come to the target idea, but it can also be evaluated at a given cut-off rank, considering only the topmost results returned by the system. This measure is called precision at n or P@n.
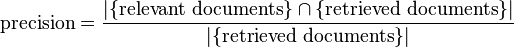
Recall:
Recall in information retrieval is the fraction of the documents that are relevant to the query that are successfully retrieved. Recall measures how well a search finds every possible document that could be of interest to the searcher.
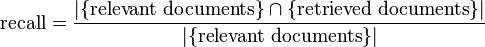
Precision Testing
First, you will first need to identify search queries that you will be using for testing. Try each of these search query in your search application, and then go through to each of the top five results. In each case, ask yourself: “How reasonable was it for the search engine to return this document based on what I entered?” Remember, you’re not after the user’s actual intention, which may not even be knowable. Instead, you’re evaluating the extent to which the answer relates to the question.
Score the relevance of each of the results on a four-letter scale:
- Relevant: Based on the information the user provided, the document’s ranking is completely relevant. This is the best score you can give, and means that the result is exactly right.
- Near: The document is not a perfect match, but it is clearly reasonable for it to be ranked highly. No one would be surprised that the search term brought back such a result.
- Misplaced: You can see why the search engine returned the result, but it clearly shouldn’t be ranked highly.(Right word, wrong idea.)
- Irrelevant: The result has no apparent relationship to the user’s search
- Use the letter codes R, N, M, and I to record your scores. for each of the top five results for each string.
Calculating Precision
You can evaluate precision in following way,
- Strict: Accept only the results ranked R, for completely relevant. This is ultimately impossible to attain, because perfect matches sometimes aren’t even available.
- Loose: Accept both Rs and Ns. This is more realistic, and a reasonable expectation to set for a search engine.
- Permissive: Accept Rs, Ns, and Ms. This is the bare minimum to which the search engine should perform, because it means that no crazy results were returned.
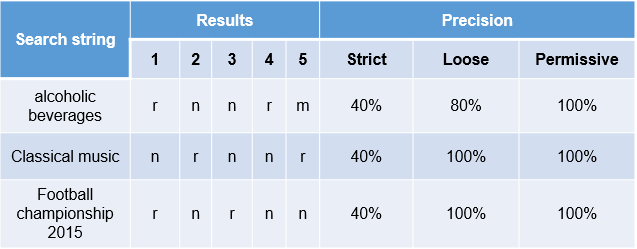
And we can calculate average precision by taking an average of each category,
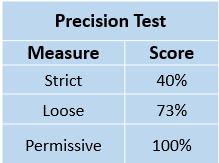
Conclusion: Precision testing tells a compelling story of the quality of the search experience. We can use precision testing results to track and improve the relevancy of our application.
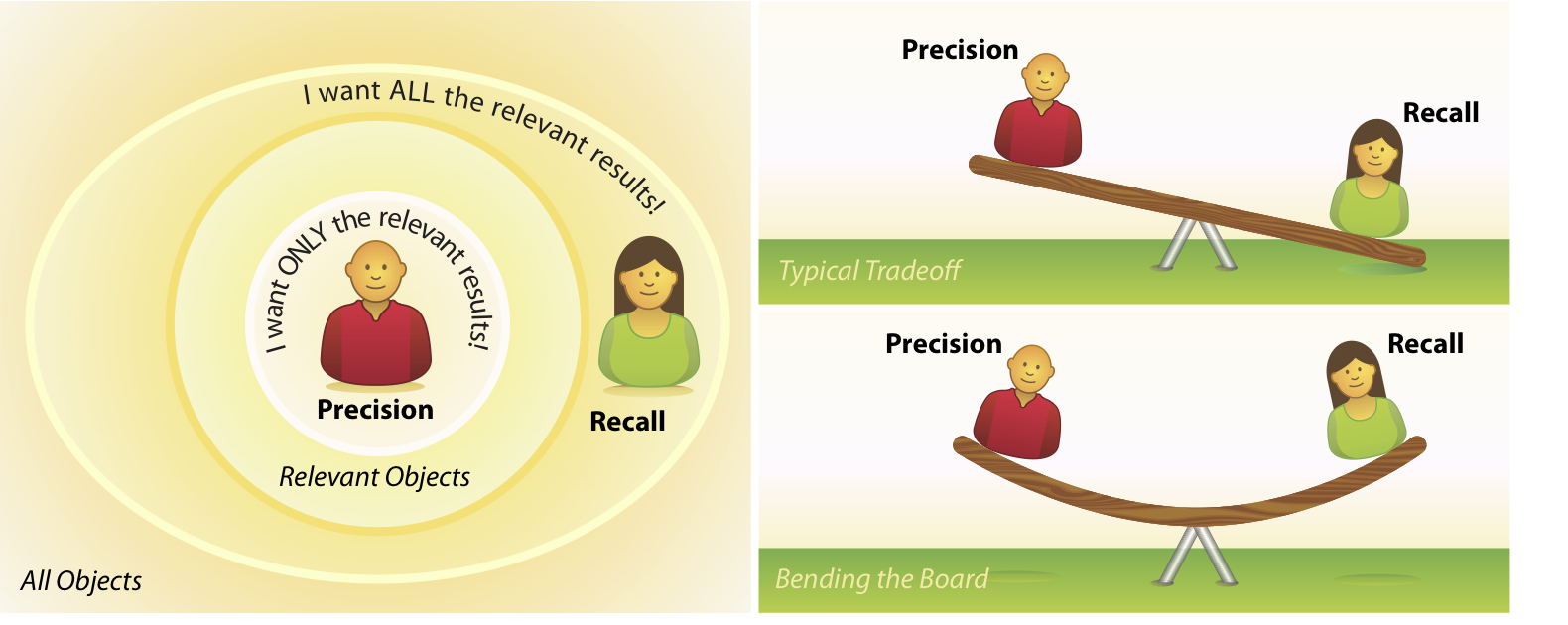
The right balance between precision and recall is very important. You can’t have both great recall and great precision, so you have to balance the two.
Write a comment
- Sanchita Sharma May 28, 2015, 10:59 amHey Vijay..your blog is very informative.reply
Subscribe To Our Newsletter
Join our mailing list to receive the latest blogs and updates.