Understanding Onion Architecture

In this post I am going to talk about Onion Architecture. There are several traditional architectures that exists in web world and each one of the architecture comes with its pros and cons. But most of the traditional architectures raises fundamental issues like tight coupling and separation of concerns. I am going to talk about issues faced with traditional designs and then we will see how Onion Architecture addresses these common issues.
Problems
The traditional and most commonly used web application architecture is Model-View-Controller architecture which is one of the most widely adapted and appreciated architecture throughout the industry. If you have been using Asp.net web forms to develop web application then adopting MVC architecture even fits better, because it provides the required framework to build web apps MVC way. But things doesn’t turn out as planned and leads to very tight coupling between UI and business logic and business logic to database logic. This is because you end up writing all of your logic in server side code (mainly aspx.cs files). This scenario produces very tight coupling over the period of time and system becomes a nightmare to maintain.
Another approach to look at the problems described above is to look at the Traditional Architecture diagram below. As you see, the UI is talking to business logic and business logic is talking to data layer and all the layers are mixed up and depend heavily on each other. None of the layer stand independent, which raises separation of concerns.
{
In other words, if your application has several lines of code in button_submit or page_load events and if it’s doing several things in one single method, then it’s a matter of concern. Because sooner or later system will change and new developers will keep adding new business logic to these existing events, and the eventual situation would be very chaotic. Such systems are always very hard to understand and maintain.
}

Further, the biggest drawback of this architecture is unnecessary coupling that it creates. Each layer is coupled to the layers below it, which creates a very tight coupling between these layers, and a tightly coupled system enforces several restrictions and challenges when undergoing changes.
The biggest offender is the coupling of UI and business logic to data access. Typically, The data access changes every few years, historically, the industry has modified the data access techniques at least every three years, so naturally, and it is expected to have some flexibility with data access layer when the system undergoes changes. However, the flexibility with technology upgrades doesn’t come handy with tightly coupled systems. There are always challenges involved changing something which has lot of impact in business critical systems and that’s where these systems fall behind the technology upgrade race and eventually becomes stale and very hard to maintain.
Solution
This is where the Onion Architecture comes in. The term “Onion Architecture” was first coined by Jeffry Palermo back in 2008 in a series of blog posts. The architecture is intended to address the challenges faced with traditional architectures and the common problems like coupling and separation of concerns.

Shown above is the proposed Onion Architecture, which has layers defined from core to Infrastructure. The main premise is that it controls coupling. The fundamental rule is that all code can depend on layers more central, but code cannot depend on layers further out from the core. In other words, all coupling is toward the center. This architecture is undoubtedly biased toward object-oriented programming, and it puts objects before all others. At the very center is the domain model, which represents the business and behavior objects. Around the domain layer are other layers with more behavior. The number of layers in application will vary but domain is always at the center. The first layer around the domain is typically we would place interfaces that provides saving and retrieving behaviors, called repository interfaces. Only the interface is in the application core. Out on the edges we see UI, Infrastructure and Tests. The outer layer is reserved for things that potentially changes often, these things are intentionally isolated from the application core. Out on the edges in Infrastructure, we would find classes that implements a repository interface and these classes are coupled to particular way of Data Access, and that’s is why it resides outside the application core.
Let’s see what each of these layers represents and what should each contain.
Domain Layer – At the very core is the Domain layer which holds all of your domain objects. The idea is to have all of your domain objects at this core. Please restrict yourself by keeping just the properties or definitions inside your domain objects and not any piece of code which talks to database or has any other business functions. Besides the domain objects, you could also have domain interfaces, but just the interfaces and not any kind of implementation.

See the screenshot from the sample project that I have created using Onion Architecture, under the solution folder 01-Domain, I have got 2 projects Domain.Entities to hold domain objects and Domain.Interfaces to hold domain interfaces. The most interesting thing to notice that there are no special references in this project, and the domain objects are flat objects as they should be, without any heavy code or dependencies.
Service Interface Layer – common operations like Add, Save, Delete should go in here within interfaces. You can define your transactional interfaces like (IOrderService.SubmitOrder) here. One of the most important thing to notice here that service interfaces are kept separate from its implementation, which shows the loose coupling and separation of concerns.

Application Services Layer – the implementation of Interfaces defined in Service Interface layers comes here. The service implementation gets data from repositories and processes requests coming in from UI layer. This layer acts as a middleware to provide data from Infrastructure to UI.

Look at the references and you will realize that this layer is using domain entities, domain interfaces and service interfaces only, it has no knowledge of where the data comes and where it gets stored, the service is solely dependent on interfaces and at runtime the actual implementation objects gets assigned. Interesting? Well, look at following class to see yourself –
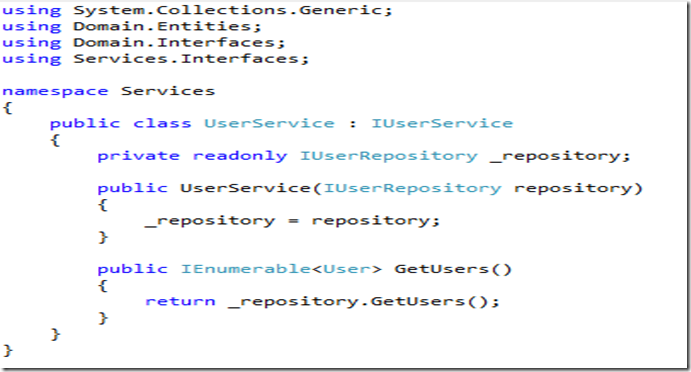
The service has dependency on the repository type (interface) which is injected at run time using Castle Windsor and all the methods works on the repository type to perform specific actions.
Infrastructure Layer – this is the outermost layer of onion architecture which deals with Infrastructure needs and provides the implementation of your repositories interfaces. In other words, this is where we hook up the Data access logic or logging logic or service calls logic. Only the infrastructure layer knows about the database and data access technology (Entity framework or Ado.net) and other layers don’t know anything about from where the data comes and how it is being stored.

Check out the code map feature of visual studio, which shows an excellent overview of sample solution with arrows pointing in dependency direction –

As you see from the diagram it is evident that not a single arrow is pointing upwards in the dependency graph. All the directions are downwards, towards domain or interfaces. Isn’t it cool?
The basic principle of Onion Architecture is to follow the boundaries of these layers – the inner layer can’t depend on its outer layer but can depend on layers beneath. For example, domain layer can’t depend on Infrastructure layer, but Infrastructure layer can depend on Domain layer. Imagine if you put the saveObjectToDatabase method in domain object, then you will depend on Infrastructure layer which is a violation of Onion Architecture. The strategy is to make interfaces defined in the domain layer and put the implementation in Infrastructure layer. Following this principle makes sure we have loose coupling between layers and a real implementation comes only at real time.
Additionally, the Onion Architecture relies heavily on the Dependency Inversion principle to provide the interface implementations at runtime. I have hooked up Castle Windsor in the sample project to achieve dependency inversion at run time. For those who are new to Castle Windsor, it is one of the best IoC container in market today. There are several others (like Ninject, StructreMap, and Unity ) also which are in market but Castle Windsor is personally my favorite.
Before closing my article – I’d like to leave you guys with one though – which is “loose coupling”. See the beauty of loose coupling achieved using this architecture. The advantages are not just limited to loose coupling but other features like Separation of concern and domain model approach makes it an awesome architecture to follow.
Take a look at the sample project available for free download at https://github.com/chetanvihite/OnionArchitecture.Sample to see Onion Architecture in action. If you have any questions please feel free to send me an email at chetan.vihite@thedigitalgroup.net.
References:
http://jeffreypalermo.com/blog/the-onion-architecture-part-1/
http://www.cunningclinton.com/post/2011/07/19/Onion-Architecture.aspx
Write a comment
- Maje May 7, 2019, 6:17 amIt was a great article and very useful for me.reply
- shreyal December 13, 2018, 9:40 amIt's very very helpful for me.reply
- Rahim November 5, 2018, 8:20 amthanks I need onion architecture sample.reply
- rasikasampath January 19, 2017, 12:01 amGot your point. Now i can see all my business logic concentrating on Services layer. (Except validation rules that are still in the MVC controller). No repositories injected in the MVC controller, only the services. Looks good. Thanks and appreciate your reply.reply
- Chetan Vihite January 18, 2017, 6:28 amthanks for your question. here is my take on having services "always" interact with controllers or for that matter any presentation layer element - having repository directly injected in the controller challenges the architecture and doesn't solve the separation of concerns. here is how - if I inject my repository directly into controller then it will be tightly coupled with controller logic, most of the developers will end up using the repository as a place to add business rules, which is not quite right. what if I change my repository? well, in that case, I will have to either duplicate the business logic code to all the repositories implementing the contract. so this way, my business logic will end up at both the places ( i.e. repository as well as the controller) which again violates DRY( don't repeat yourself). another advantage this brings in is the testability - the services along with business logic can be tested independently without having an actual repository in place ( TDD approach ). so, we should stick to writing services which deal with encapsulating repositories calls as well as handle business logic. this way we define the purpose of each of the layer perfectly and in long run this architecture will be able to handle future maintenance elegantly. hope this helps.reply
- rasikasampath January 17, 2017, 9:11 pmBased upon your example, what if I inject the UserRepository at the MVC controller and use it? As i can see the UserService class here is only encapsulating the UserRepository, so I think creating another layer of service class for each repository is not quite right. For example if you need to send an email after the registration, then it make sense to have a UserService which acceptes IUserRepository and another interface for sending emails (INotifier), where you will be able to include your business logic. Can you please share your thoughts on this. Thanksreply
- Thuan Pham January 17, 2017, 2:32 amYour're amazing, It's very very helpful for me.reply
- Emmanuel Istace January 2, 2017, 6:55 pmI feel like this is a totally legit and natural architecture but, in a ways, it's just 3-tier MVC architecture with DI and SOLID in mind, I don't see what's revolutionary here :/reply
- Allie December 22, 2016, 6:53 pmIn the diagram listing the .dll's and their dependencies, I noticed there's no arrow from the OnionArchitecture.Sample.dll to Domain.Entities. Wouldn't the top layer need a dependency on the entities in order to use the return values of the Repo's? Or am I missing something?reply
- Santiago December 20, 2016, 10:06 am<cite>The most interesting thing to notice that there are no special references in this project, and the domain objects are flat objects as they should be, without any heavy code or dependencies.</cite> Domain objects shouldn’t be flat objects without any logic as you said. All business logic and behavior should be encoded on the domain layer.reply
- Santiago December 20, 2016, 10:04 am<blockquote cite="The most interesting thing to notice that there are no special references in this project, and the domain objects are flat objects as they should be, without any heavy code or dependencies." /> Domain objects shouldn't be flat objects without any logic as you said. All business logic and behavior should be encoded on the domain layer.reply
- Jeremy Stafford October 21, 2016, 4:20 amThe problem here, I think is that while the architecture doesn't permit the top layer from talking to (or referencing) the domain, the sample project does exactly that, pretty much pulling the guts out.reply
- OnionFAN May 19, 2016, 10:00 pmI really appreciate this article. Really good example.reply
- OnionFAN May 19, 2016, 9:59 pmI really appreciate this article. Perfect Example.reply
- Shirley April 29, 2016, 2:12 pmMighty useful. Make no mistake, I appiacrete it.reply
- genhacks24.com October 31, 2015, 10:07 pmIt’s hard to find experienced people with this topic, however you sound like you know what you’re referring to! Thanksreply
- A Technology (Microsoft Technologies) Architect’s Confession | Insight's Delight August 27, 2015, 4:11 am[…] here and here. b) Architectural Patterns and Styles (including Hexagonal Architecture and Onion Architecture), OReilly Software Architecture Series, 97 Things Every Software Architect Should Know, […]reply
Subscribe To Our Newsletter
Join our mailing list to receive the latest blogs and updates.