Content Classification: The Backbone of Text Mining

What is Content Classification in Text Mining?
Content classification in text mining is like sorting through a massive library of books and organizing them into proper labelled shelves. Now imaging having thousands of documents, emails, or social media posts, and needing to categorize them based on their content. That’s why content classification is important, using advanced algorithms to automatically sort text into predefined categories. Think of it as giving each piece of text a “home” where it belongs, based on its meaning and context.
Why Does Content Classification Matters?
At this moment content classification might sound fancy for some, but I am sure you’ve interacted with it more times than you realize. For instance:
- Ever wondered how your email app knows to dump spam into the “Junk” folder?
- How your favourite video steaming app suggests a rom-com just when you’re craving for popcorn? Yes, that’s it too.
- Even search engines- when they deliver that best-fit webpage – rely on categorizing billions of text documents.
Simply put, content classification helps machines “understand” the text’s meaning so they can make decisions or manage data. There are many more examples, you can share in the comment box.
How Does Exactly Content Classification Work?
Content Classification depends on Natural Language Processing (NLP) and machine learning (ML) to group text. Here’s the step-by-step process of content classification:
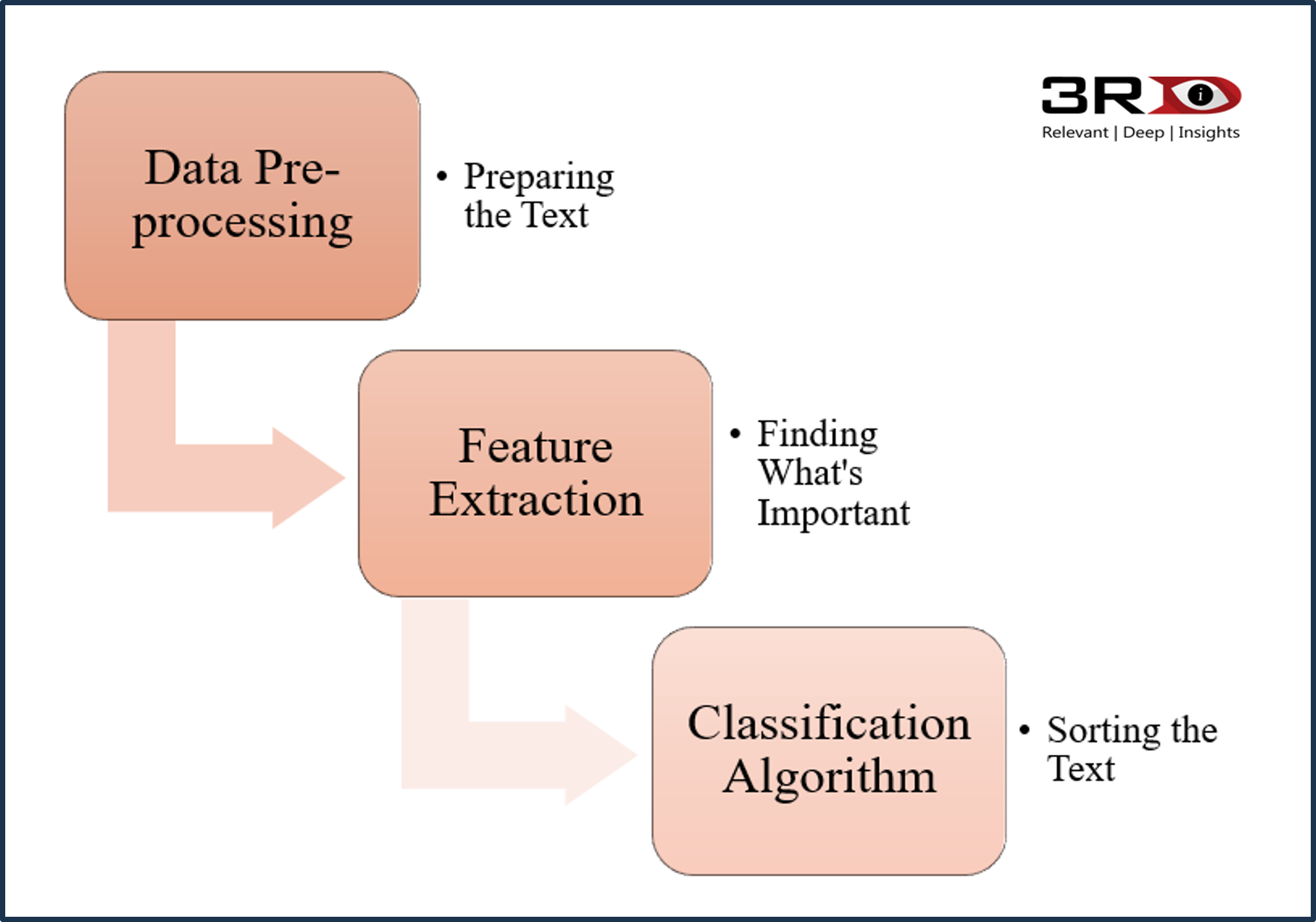
Steps in Content Classification
Data Pre-processing
This is like cleaning up a cluttered room before categorizing it. Pre-processing removes stop words (common words like “the” or “and”), punctuation, and irrelevant details. Techniques such as stemming and lemmatization easy words – so “running” becomes “run.”
Feature Extraction
Next, the system extracts key features of the text. It’s like focusing on exact keywords and neglecting unnecessary. Common techniques include:
- Bag of Words (BoW): Counts words frequency but neglects word sequence.
- TF-IDF (Term Frequency-Inverse Document Frequency): Emphasizing words that are unique and less common across documents.
Classification Algorithm: Sorting the Text
Classification Algorithm is the most crucial phase. Algorithms such as Naïve Bayes, Support Vector Machines (SVM), or neural networks categorize the text. Here are some use cases:
Algorithm | Use Cases |
Naive Bayes | Spam Email Detection |
Support Vector Machines (SVM) | Document Classification |
Neural Networks | Image Captions in Texts |
Here’s the process of content classification in explained in simple form-
[Raw Text Input] -> [Data Pre-processing] -> [Feature Extraction] -> [Classification Algorithm] -> [Categorized Output]
Types of Content Classification

Rule-Based Classification
In Rule-based classification, a system uses a set of pre-defined rules to group content. For instance, if you need something related to “budget” will be categorized into the Finance section. While it’s easy, it can’t handle nuanced or evolving data.
Machine Learning-Based Classification
Here’s where things get more interesting! Machine learning models learn from training data. You feed them examples of text and the corresponding categories, and they classify how to label new text automatically.
Hybrid Classification
As the name suggests, Hybrid classification combines rule-based methods with ML. It’s the best of both worlds and it especially helpful in complex industries such as healthcare.
Latent Dirichlet Allocation
Latent Dirichlet Allocation (LDA) is a Bayesian network model which finds topics in a collection of documents. It is a three-level hierarchical model that uses word, topic, and document layers to build a latent topic structure. LDA assumes that each doc is a mixture of topics, and each topic is a mixture of words. Further it randomly assigns each word in a document to a topic, then reassigns words based on how prevalent the topic is in the document and how prevalent the word is across topics. It is widely incorporated in NLPs and context-aware recommendation system. Additionally, LDA is a generative model that doesn’t need known class labels, so it avoids making strong assumptions regarding the relationship between text and categories. Let’s checkout few examples.
Examples of Latent Dirichlet Allocation
Text | Category |
Stock markets rallied after the budget announcement. | Finance |
Top 10 healthy recipes for weight loss | Lifestyle |
Why AI is reshaping the future of healthcare | Technology |
In a research, it was found that machine learning-based classification improved text categorization accuracy by 20% compared to conventional rule-based systems. That’s a huge leap!
What is Retina API?
The Retina API, developed by 3RDi Search Enterprise, is an all-in-one Natural Language Processing (NLP) and Text Analysis engine crafted to improve search experiences by extracting meaningful insights from unstructured content. Their Named Entity Recognition (NER) identifies and classifies entities like names, organization, and locations within text, facilitating structured data extraction.
Sentiment Analysis evaluates the sentiment expressed in text, determining whether it is positive, negative, or neutral, which is important for understanding customer feedback and social media monitoring. Its content classification feature categorizes Text into predefined topics or categories, aiding in content organization & management.
Semantic similarity assesses the similarity between texts, allowing tasks such as duplicate content detection and document clustering. The content summarization generates concise summaries of longer texts, helping users to easily understand essential information. Ontology and Linked Open Data (LOD) Mapping aligns content with specific ontologies and integrates with external data sources, improving semantic enrichment and contextual understanding.
3RDi Search’s Retina API is pre-configured with an extensive set of thesauri and taxonomies and can be integrated with custom legacy vocabularies, providing feasible semantic enrichment adaptable to various domains.
For organizations looking to improve their text analysis capabilities, Retina API gives a strong solution for text mining. A live demo is available upon request. Click on the link below to request live demo session- www.3rdisearch.com/request-live-demo-3rdi-enterprise-search-tool.
Write a comment
Subscribe To Our Newsletter
Join our mailing list to receive the latest blogs and updates.