Introduction to OrientDB

Background
Recently I started looking into OrientDB for one the use case at TDG where we were evaluating which NOSQL database to go for. As I came across OrientDB & learned more about it, I see it quite promising. I wonder why this hybrid mode of combining the document model with graph model in conjunction with relational model was not thought before. Hats off to OrientDB team for coming up with 2nd generation distributed graph database.
I personally have interests in data structures (trees / graphs etc.) but never thought that using the vertex & edges, we not only can represent relationships but also solve the database join issue which is the key bottleneck in making relational databases to scale / distributed ( See http://www.slideshare.net/lvca/why-relationships-are-cool-but-join-sucks-28997951 )
What it means is you can represent relational model (e.g. popular employee-department use case) in document-graph model maintaining the relationships and able to perform all sorts of CRUD & query operations. All CRUD / query operations are allowed through SQL which in general is common skill set and on top of that OrientDB provides you OOPS features like inheritance & polymorphism. Isn’t that exciting???
Working with document-graph database will require little different mindset but is intuitive enough for anyone familiar with relational & document model. Let’s discuss this briefly in the next section Data Modeling.
Data Modeling
Let’s take a journey of 3 different modeling world before we model in OrientDB
Relational World (Oracle, MySQL etc…)
– A table contains records (or data)
– A table has defined schema (fields & types)
– Data is normalized to avoid duplicity of data as a result of which data gets broken into different tables.
– Then How the data is represented as a whole / unit – You introduce a common field/key to join various tables. The common key expresses the relationship between two data sets.
NOSQL Document World (MongoDb)
– A collection (table) contains documents (records)
– A document has flexible schema (or schema less)
– A document contains pairs of fields & values in JSON-style
– Data can be split into different collections(or documents) or embed as nested documents. Each collection will hold similar set of documents (shared common index)
Graph World (OrientDB)
– A vertex (record) contains data and has properties & values (similar to a document)
– A vertex is also called Node
– A vertex may have incoming & outgoing Edges
– Each vertex has record id/rid consist of cluster id & position (e.g. #12:0)
– Relationship between two different vertex/documents are expressed more naturally via Edges (as oppose to a common key/field in Relational world). e.g.Employee WorksAt Department where Employee & Department are vertices & Edge is WorksAt
– Both Vertex & Edge can have properties
– OrientDB allows schema-less, schema-full & schema-mix model
Modeling with OrientDB
Vertex (V), Edge(E) & Class are basic building blocks in OrientDB data modeling. Before we create Vertex/record we need to define what type of data it can contain. This is done using Class which every OOPS developer is aware of.
So taking an employee department example, you would first create a class called Employee and add Properties to it. The instance of this class will be a Vertex (or record). Note: All Vertex class must extends from V. Similarly you will create class Department and add properties to it. So now you have two sets of Vertices but there is no relationship (who works in which department?). Now you will create a Edge class extends from E and instance of it will represent an Edge. See below diagram.
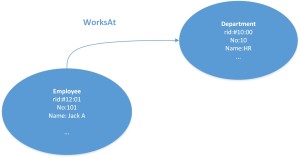
Part of data modeling you also need to consider which cluster your data should reside in when defining the class but is out of scope for this blog.
Let’s now get into setting up OrientDB & run thru live examples to cover the employee-department data modeling.
Setup & Run OrientDB
You may download from http://orientdb.com/download/ & run OrientDB server & launch console from bin directory.
$./server.sh
$./console.sh
orientdb>
To connect to orientdb server, you can launch connect command like below
orientdb>connect remote:localhost root root
orientdb {server=remote:localhost/}>
At this point you are connected to OrientDB and you can list databases or create or connect to one of them.
Create Database
Before we create any database, lets look the existing databases
orientdb {server=remote:localhost/}> list databases;
….
Now create a database called empdb
orientdb {server=remote:localhost/}>create database remote:localhost/empdb root root plocal
….
and you will be connected to employee database.
orientdb {db=empdb}>
Create a class Person and add two properties lastName & firstName using below commands
orientdb {db=empdb}> create class Person extends V;
orientdb {db=empdb}> create property Person.lastName string;
orientdb {db=empdb}> create property Person.firstName string;
Create a class Employee which extends from Person & add few properties to it
orientdb {db=empdb}> create class Employee extends Person;
orientdb {db=empdb}> create property Employee.empno integer;
orientdb {db=empdb}> create property Employee.sal integer;
Create a class Department extends from V
orientdb {db=empdb}> create class Department extends V;
orientdb {db=empdb}> create property Department.deptno integer;
orientdb {db=empdb}> create property Department.name string;
If you noticed we used Inheritance above when creating Employee class by extending it from Person. That’s a cool feature!!! Now we have classes to represent vertex (a document) & let’s create a class to represent Edge to establish the relationship.
orientdb {db=empdb}> create class WorksAt extends E;
So now we are all set to add/create data to graph model we create above.
Let’s create some employees (vertex or document)
orientdb {db=empdb}> create vertex Employee set empno=101,firstName=’John’,lastName=’Jacob’,sal=5000;
Created vertex ‘Employee#12:0{empno:101,firstName:John,lastName:Jacob,sal:5000} v1? in 0.003000 sec(s).
orientdb {db=empdb}> create vertex Employee set empno=102,firstName=’Adam’,lastName=’Bill’,sal=7000;
Created vertex ‘Employee#12:1{empno:102,firstName:Adam,lastName:Bill,sal:7000} v1? in 0.002000 sec(s).
orientdb {db=empdb}> create vertex Employee set empno=103,firstName=’David’,lastName=’Manon’,sal=4000;
Created vertex ‘Employee#12:2{empno:103,firstName:David,lastName:Manon,sal:4000} v1? in 0.002000 sec(s).
Similarly lets create some departments
orientdb {db=empdb}> create vertex Department set deptno=10,name=’Accounts';
Created vertex ‘Department#13:0{deptno:10,name:Accounts} v1? in 0.002000 sec(s).
orientdb {db=empdb}> create vertex Department set deptno=20,name=’HR';
Created vertex ‘Department#13:1{deptno:20,name:HR} v1? in 0.002000 sec(s).
orientdb {db=empdb}> create vertex Department set deptno=20,name=’IT';
Created vertex ‘Department#13:2{deptno:20,name:IT} v1? in 0.001000 sec(s).
Now time to establish relationship. Create some Edges
orientdb {db=empdb}> create Edge WorksAt from #12:0 to #13:1;
orientdb {db=empdb}> create Edge WorksAt from #12:1 to #13:0;
orientdb {db=empdb}> create Edge WorksAt from #12:2 to #13:2;
You will notice that creating Edge requires rid (clusterid:position) to be specified for Edge to know which two vertices to connect. This rid you can find when you created the vertex or by query or by visiting to OrientDB studio.
Now its time to visualize the graph created. We can use Graph view of OrientDB Studio (Visit http://localhost:2480 in browser and then select empdb with credentials supplied during database creation)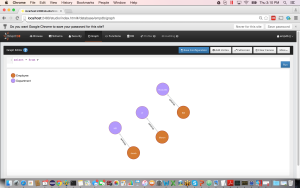
Querying Graph
So far we have been using orientdb console to execute the queries but other option is to execute using OrientDB Studio Browse tab which I would recommend for below queries as console doesn’t results in some cases properly.
Show all employees
select * from Employee;
Show sum of Salaries of all employees
select sum(sal) from Employee;
Show employees & their departments (similar to joining the two tables)
This one is interesting since i would like to show the comparison between how you would do this typically in Relational world vs Graph world
In RDBMS world
select e.empno,e.lastName,e.firstName,d.deptname
from employee e, department d
where e.empno=d.empno;
In OrientDB world
select empno,lastName,firstName,out(“WorksAt”).include(“name”).name[0] as deptname from Employee
Basically we are selecting the properties(columns) from Employee and then using out() function getting all the adjacent (linked) vertices with Edge WorksAt and including only name from department vertices.
Show employees who works in more than one department
Create an employee that we can query for
> create Edge WorksAt from #12:0 to #13:2;
In RDBMS you will use query like below
mysql> select e.empno from employee e, department d where e.empno = d.empno group by d.empno having count(d.empno)>1;
In OrientDB, below query would do the same by checking the number of outgoing edges from each vertex(record) and select if it is greater than 1
select lastName,firstName from Employee where out(‘WorksAt’).size() >1
Show department having more than 4 employees
Create few more employees that we can perform such query and the graph will look like below
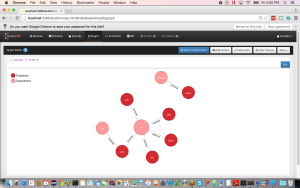
orientdb {db=empdb}> create vertex Employee set id=104,lastName=’kelly’,firstName=’kim’,sal=3500;
…
select name from Department where in(‘WorksAt’).size() > 4
CRUD operations
OrientDB SQL CRUD operations are very similar to traditional SQL
C – create vertex employee set id=101,lastName=’Johnson’…
C – insert into employee(empno,firstName) values(107,’Mike’);
U/R – update Employee set empno=105 where firstName=’Mike’
D – delete vertex employee where empno is null;
API Options / Integration
Its all good to use SQL in OrientDB but when it comes to integrate or use OrientDB in presentation or business layer following are the choices
OrientDB provides 3 Java APIs for integration if you are planing to integrate from Java based applications
Graph API
Document API
Object API
Using Graph API is suggested and more common but depending on the use case have you may want to use other APIs. For detailed comparison please refer OrientDB docs http://orientdb.com/docs/2.1/Java-API.html
The other option for not using Java API is to use HTTP Rest/JSON API. You may want to download POSTMAN Chrome extension to work with OrientDB and using the HTTP Interface. POSTMAN allows you to connect and maintain the session that you can subsequently issue SQL queries over HTTP and get back the results in JSON format.
Transactions in OrientDB
One of the key feature OrientDB provides is the ability to perform transactions which is unique if compare to NOSQL world where transactions/ACID property is compromised for scaling / distributed purpose. OrientDB is ACID Compliant database. Below is example snippet.
db.open(“remote:localhost:2480/Account”);
try{
db.begin(…);
…
deduct from account A
calculate
add to account B
// WRITE HERE YOUR TRANSACTION LOGIC
…
db.commit();
}catch( Exception e ){
db.rollback();
} finally{
db.close();
Distributed Transactions
OrientDB supports distributed transactions where after commit, all the updated records are sent across all the servers, so each server can commit. If any of the node(s) can not commit the quorum(majority) is checked and accordingly either everything is rolled back or nodes which couldn’t commit aligns with successful nodes
Also part of Distributed Architecture Hazelcast a operational in-memory computing platform is used by OrientDB to manage the clusters
Summary
In this blog, I have covered OrientDB background, data modeling & comparison of relational, nosql & graph model, setting up & running orientdb, creating orientdb database & its elements & querying graph model in comparison with relational model. I will add some more use cases on hierarchal data and hoping that above intro gives you some quick good insight into OrientDB.
References
http://orientdb.com/docs/
https://www.udemy.com/orientdb-getting-started/learn/#/
Write a comment
Subscribe To Our Newsletter
Join our mailing list to receive the latest blogs and updates.