Named Entity Recognition

NER describes the concept of annotating sequences of words in a text.
NER systems taking an unannotated block of text as an input for processing
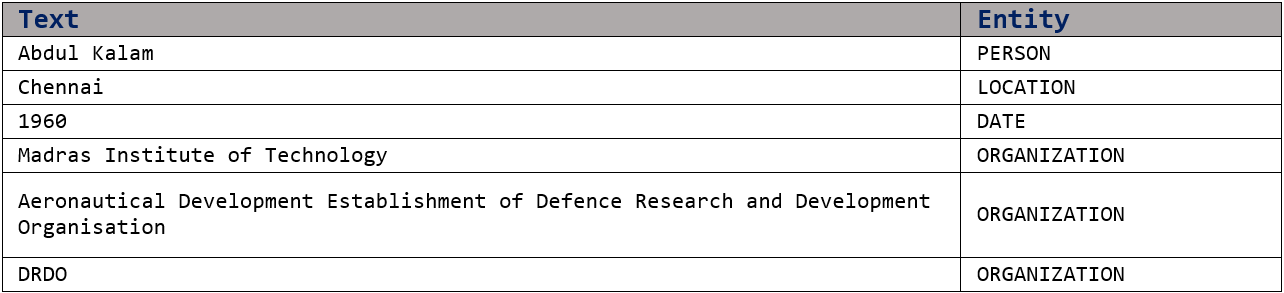
“After graduating from Madras Institute of Technology (MIT – Chennai) in 1960, Dr. Abdul Kalam joined Aeronautical Development Establishment of Defence Research and Development Organisation (DRDO) as a scientist.”
Useful:
- To identify what a document is about.
- To enhance search retrieval in terms of faceting.
- To boost the document for result ranking.
- For linking documents based on the concepts within them.
- GATE supports NER across many languages and domains out of the box, usable via graphical interface and also Java API
- NETagger includes the Java based Illinois Named Entity Recognition tool, trained for the standard 4 types, as well as for an extended set of entities.
- OpenNLP includes rule based and statistical named entity recognition
- Stanford CoreNLP includes a Java-based CRF named entity recognition tool
- 3 class model : Location, Person, Organization
- 4 class model : Location, Person, Organization, Misc
- 7 class model : Time, Location, Organization, Person, Money, Percent, Date
- stanford-corenlp-[version].jar
- NER Classifier – english.all.7class.distsim.crf.ser.gz
static String DIR_PATH = "ner";
static String NER_CLASSIFIER_FILE = "english.all.7class.distsim.crf.ser.gz";
static AbstractSequenceClassifier < CoreMap > classifier = null;
static {
try {
String classifierPath = DIR_PATH + File.separator +
NER_CLASSIFIER_FILE;
if (!new File(classifierPath).exists()) {
System.out.println(classifierPath + " does not exists.");
} else {
classifierPath = URLDecoder.decode(classifierPath, "UTF-8");
classifier = CRFClassifier
.getClassifierNoExceptions(classifierPath);
}
} catch (Exception e) {
e.printStackTrace();
}
}
String text = query;
String output = null;
try {
if ((text != null && !text.equals("")) && classifier != null) {
output = classifier.classifyToString(text);
System.out.println(output);
}
} catch (Exception e) {
e.printStackTrace();
}
return output;
}
String[] ENTITY_LIST = {
"person",
"location",
"date",
"organization",
"time",
"money",
"percentage"
};
try {
if (text != null) {
for (String entityValue: ENTITY_LIST) {
String entity = entityValue.toUpperCase();
Pattern pattern = Pattern
.compile("([a-zA-Z0-9.%]+(/" + entity +
")[ ]*)*[a-zA-Z0-9.%]+(/" + entity + ")");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start = matcher.start();
int end = matcher.end();
String inputText = text.substring(start, end);
inputText = inputText.replaceAll("/" + entity, "");
System.out.println(inputText + " : " + entity);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
Write a comment
Subscribe To Our Newsletter
Join our mailing list to receive the latest blogs and updates.