LIRE: Lucene Image Retrieval

LIRE is a Java library that provides a simple way to retrieve images based on their colours and texture features. LIRE creates a Lucene index of image features for content based image retrieval (CBIR). Due to its modular nature it can be used on process level (e.g. index images and search) as well as on image feature level. Developers and researchers can easily extend and modify LIRE to adapt it to their needs.
LIRE provides a extensive range of image features comprising of colours and texture features, correlograms, joint histograms, region and edge features as well as several different metrics for distance computation.
List of some features:
1. ScalableColor, ColorLayout and EdgeHistogram MPEG-7
2. Color and edge directivity descriptor (CEDD) and Fuzzy color and texture histogram (FCTH)
3.Color histograms (HSV and RGB), Tamura & Gabor, auto color correlogram, JPEG coefficient histogram (common global descriptors)
4. Visual words based on Scale-invariant feature transform(SIFT) and Speeded up robust features (SURF)
5. Approximate fast search based on hashing and metric indexing.
6. Pyramid Histogram of Oriented Gradients (PHOG)
_________________________________________________________________________________________________
METHODICAL DETAILS
LIRE is built on top of the open source text search engine Lucene, hosted at http://lucene.apache.org. Like in text retrieval images have to be indexed for later retrieval.
The index is prepared as a Lucene index, where documents consisting of fields each having a name and a value are organized in an index structure typically stored in the file system.
Internal working of LIRE:
In general LIRE takes numeric images descriptors, which are mainly vectors or sets of vectors, and stores them inside a Lucene index as text along with the image path within a Lucene document. So it’s like a very primitive database.
Example: Assuming that an image has a dominant colour the RGB values of the dominant colour are stored in Lucene. The index for 3 photos might look like this:
1. document1 = {path=Image1.jpg, dominantcolor=10, 120, 30}
2. document2 = {path= Image2.jpg, dominantcolor=200, 24, 90}
3. document3 = {path= Image3.jpg, dominantcolor=10, 139, 22}
An IndexSearcher in case of a search opens every single document within the index, parses the vector and compares it to the query vector (e.g. with an L1 distance). The best matching documents are stored in a result vector along with the distance.
___________________________________________________________________________________________________
LIRE IMPLEMENTATION DETAILS
Indexing
- Indexing is done using an implementation of the DocumentBuilder interface.
- It uses the DocumentBuilderFactory, which creates DocumentBuilder instances for all available features as well as popular combinations of features.
- A DocumentBuilder is basically a wrapper for image features creating a Lucene Document from a Java BufferedImage.
- The signatures or vectors extracted by the feature implementations are wrapped in the documents as text. The document output by a DocumentBuilder can be added to a Lucene index.
Parallel Indexing
- If you have multiple CPU cores you can use the parallel indexing
- It required to configure the number of consumer threads.
- There will be a monitor thread, a main thread as well as a producer thread too. However, only the n consumer threads plus the one producer thread will create CPU load, whereas the producer will just read and put it into a queue.
Searching
Basic search implementations use linear search to find the most promising n candidates and return them in a ranked list.
- For search, it implements the ImageSearcher interface.
- The ImageSearcher either takes the given query feature or extracts the feature from a query image.
- It then reads documents from the index sequentially and compares them to the query image (linear search).
- Although the main indexing features of Lucene (e.g. an inverted list or stemming) are not employed in this kind of search, LIRe takes advantage of the efficient and fast disk access layer of Lucene, which results in lower search times compared to implementations using the embedded databases HSQLDB2.
Re-ranking Features
LIRE permits to create a ranked list of results based on some similarity metric along with a low level image feature. But, sometimes need a filtering or re-ranking process to take place later.
- Scenario: If Lire search is applied to a large database on a fast but not very precise feature (e.g. hashing) and the resulting list has to be re-ranked according to a global feature, so re-ranking can also applied to extended analysis method like latent semantic analysis (LSA).
Bag of Visual Words (BoVW)
1) Indexing: Lire supports creation of a bag of visual words index and search within. You need to index documents the traditional way first and you have to take care of creating the right local features. This basically means that you’ll need to use the SurfDocumentBuilder to get the local features for later Bag of Visual Words indexing based on SURF features
This approach has been designed for big data sets. Therefore the implementation will not work properly with small data sets and usage will lead to errors and warnings.
2) Searching: The approach implemented in LIRE is the metric spaces method. It utilizes inverted lists to describe data points in feature spaces by their distance to a set of reference data points. Utilizing a ranked list of nearest neighbour’s the foot-rule distance provides an approximation of the original pair wise distance. This approach has been shown to work well on sets of millions of images.
- With the VisualWordsImageSearcher class search in BoVW indexes. Requied to take a document from the index for a query
3) Incremental Update: Let’s assume you have already indexed additional documents with the SurfDocumentBuilder, so they are in the index, but do not have visual words attached yet, then it can be achieved by using:
- Need to create a new (or use the old) SurfFeatureHistogramBuilder and employ the indexMissing methods.
The constructor parameters do not matter in this case as they are read from disk in the course of the indexMissing method.
___________________________________________________________________________________________________
LIRE GUI
It provides a simple GUI interface for
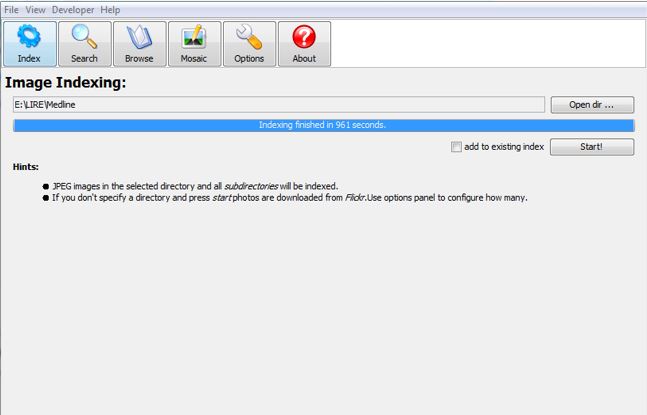
• Indexing Image
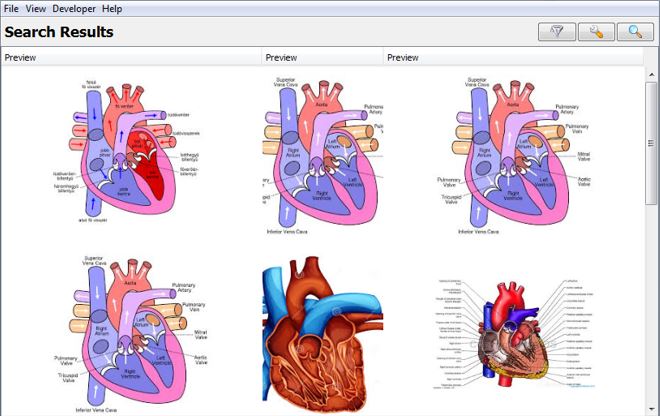
• Searching Image
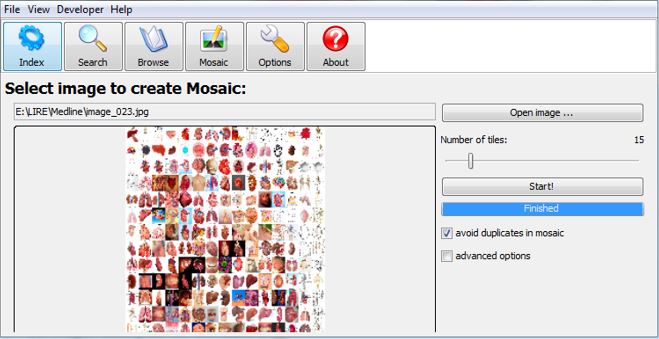
• Creating mosaic images based on indexed images
PERFORMANCE
For testing runtime performance of indexing 1,000 images is feed to LireDemo. Indexing completed in 961 seconds.
System configuration: All test have been done on a desktop computer with an Intel Core i3 CPU with 2.4 GHz and 8 GB RAM running on 64 bit operating system (Windows 7) having Java 1.6 installed. The test was done in a single thread with Java client.
REFERENCES
1) http://www.semanticmetadata.net/wiki/
2) http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.447.7417&rep=rep1&type=pdf
3) http://sigmm.org/records/records1104/featured01.html
Write a comment
- lasertest August 22, 2015, 2:01 amI feel this is one of the such a lot important info for me. And i'm happy reading your article. But want to observation on few common issues, The web site taste is great, the articles is actually nice : D. Good task, cheersreply
- google trends July 9, 2015, 6:57 pmExcellent post! We will be linking to this great post on our site. Keep up the good writing.reply
Subscribe To Our Newsletter
Join our mailing list to receive the latest blogs and updates.