Supervised Learning for Text Classification
Text Classification (or Categorization) has been investigated by many researchers over more than past 2 decades. Due to the extreme increase in online textual information, e.g. Email messages, online news, web pages, as well as a huge number of resources for scientific online abstracts such as MEDLINE, there is an ever-growing demand for Text Classification. It is an interesting question how to achieve high performance in the task of assigning multiple topics to documents in a targeted domain and how to make the most of the multi-topical features of the documents.
Text categorization is the grouping of documents into a fixed number of predefined classes. Each document can be in multiple, exactly one, or no category at all. Using machine learning, the objective is to classifiers from examples which perform the category tasks automatically. This is a supervised learning problem. Since categories may overlap, each category is treated as a separate group.
Supervised Learning for Text Classification.
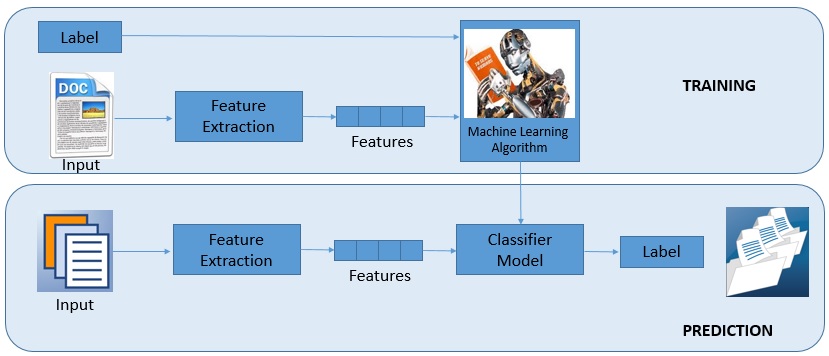
PART-I : Training
1) During training, a feature extractor is used to transform each input value to a feature set.
2) These feature sets, which capture the basic information about each input that should be used to categorize it.
3) Pairs of feature sets and labels are fed into the machine learning algorithm to produce a model.
PART-II : Prediction
1) During prediction, the same feature extractor is used to transform unobserved inputs to feature sets. These feature sets are then fed into the model, which produces predicted labels.
Implementation of Text Classification using Naive Bayes Classifier.
What is the Naive Bayes Classifier?
The Naive Bayes classifier is a simple probabilistic classifier which is based on Bayes theorem with strong and naive independence assumptions. It is one of the most basic text classification techniques with various applications in email spam detection, document categorization, language detection, sentiment detection and automatic medical diagnosis. It is one of the most basic text classification techniques used in various applications. It is highly scalable.
Process flow for the Text classification.
For performing the Text classification using Naïve Bayes on Text data required some additional packages, which need to install such as tm, e1071, SparseM. In this process data is stored in .csv file is used.
Step 1: Reading the Data from .csv file.
Step 2: Divide the dataset into two parts as training dataset and testing dataset.
Step 3: Create a corpus for training dataset and testing dataset.
Step 4: Performing the Data processing transformation on the training dataset and testing datasets.
1. Transform characters to lower case.
2. Converting to Plain Text Document.
3. Remove punctuation marks.
4. Remove digits from the documents.
5. Remove from the documents words which we find redundant for text mining (e.g.
Pronouns, conjunctions). We set this words as stopwords(“English”) which is a built-in list for English language.
6. Remove extra whitespaces from the documents.
Step 5: Now create the “Term document matrix”. It describes the frequency of each term in each document in the corpus and perform the transposition of it.
Step 6: Train Naïve Bayes model using transposed “Term document matrix” data and
Target class vector.
Step 7: Apply the prediction on generated model for testing dataset.
Implementation in R:
library('e1071');
library('SparseM');
library('tm');
# LOAD DATA FROM CSV
Sample_data <- read.csv("Path of .csv file");
# CREATE DATA FRAME OF 750 TRAINING JOURNALS ARTICLES AND 250
# TEST ARTICLES INCLUDING 'Abstract'(Column 1) AND 'Journal_group' (Column 2)
traindata <- as.data.frame(Sample_data[1:750,c(1,2)]);
testdata <- as.data.frame(Sample_data[751:1000,c(1,2)]);
# SEPARATE TEXT VECTOR TO CREATE Source(),
# Corpus() CONSTRUCTOR FOR DOCUMENT TERM
# MATRIX TAKES Source()
trainvector <- as.vector(traindata$Abstract);
testvector <- as.vector(testdata$Abstract);
# CREATE SOURCE FOR VECTORS
trainsource <- VectorSource(trainvector);
testsource <- VectorSource(testvector);
# CREATE CORPUS FOR DATA
traincorpus <- Corpus(trainsource);
testcorpus <- Corpus(testsource);
# PERFORMING THE VARIOUS TRANSFORMATION on "traincorpus" and "testcorpus" DATASETS #SUCH AS TRIM WHITESPACE, REMOVE PUNCTUATION, REMOVE STOPWORDS.
traincorpus <- tm_map(traincorpus,stripWhitespace);
traincorpus <- tm_map(traincorpus,tolower);
traincorpus <- tm_map(traincorpus, removeWords,stopwords("english"));
traincorpus<- tm_map(traincorpus,removePunctuation);
traincorpus <- tm_map(traincorpus, PlainTextDocument);
testcorpus <- tm_map(testcorpus,stripWhitespace);
testcorpus <- tm_map(testcorpus,tolower);
testcorpus <- tm_map(testcorpus, removeWords,stopwords("english"));
testcorpus<- tm_map(testcorpus,removePunctuation);
testcorpus <- tm_map(testcorpus, PlainTextDocument);
# CREATE TERM DOCUMENT MATRIX
trainmatrix <- t(TermDocumentMatrix(traincorpus));
testmatrix <- t(TermDocumentMatrix(testcorpus));
# TRAIN NAIVE BAYES MODEL USING trainmatrix DATA AND traindate$Journal_group CLASS VECTOR
model <- naiveBayes(as.matrix(trainmatrix),as.factor(traindata$Journal_group));
# PREDICTION
results <- predict(model,as.matrix(testmatrix));
Advantages of Naïve Bayes Classifier:
• Naive Bayes is that it only needs a small amount of training data to estimate the parameters necessary for classification.
• Fast to train (single scan). Fast to classify.
• Not sensitive to irrelevant features
• Handles real and discrete data
• Handles streaming data well.
Disadvantage of Naïve Bayes Classifier:
• Assumes independence of features.
Application of Text Classification:
• Sort journals and abstracts by subject groups (e.g., MEDLINE, etc.).
• Spam filtering, a process which tries to discriminate E-mail spam messages from authentic emails.
• Language identification, automatically determining the linguistic of a text.
• Sentiment analysis, determining the attitude of a speaker or a writer with respect to some topic or the overall contextual polarity of a document.
• Article triage, selecting articles that are relevant for manual literature curation.
References:
1) http://www.textminingcentre.ac.uk/papers/Sasaki_IEEE_2007.pdf
2) http://www.nactem.ac.uk/dtc/DTC-Sasaki.pdf
3) http://www.cs.cornell.edu/people/tj/publications/joachims_98a.pdf
4) http://findicons.com/icon/19272/recherche_doc
5) http://www.twofold.co.uk/Journey-Document-Management
6) http://www.bsol.asn.au/pages/page/73/BSOL_Documents
7) http://aylien.com/classification/
8) https://code.google.com/p/rtexttools/source/browse/NaiveBayes.R?r=c8ec81e0f0c7dd089b8b44e9be360ea4617fe9d8
9) http://blog.datumbox.com/machine-learning-tutorial-the-naive-bayes-text-classifier/
10) http://www.enterrasolutions.com/2013/11/artificial-intelligence-and-machine-learning.html
11) http://www.cs.ucr.edu/~eamonn/CE/Bayesian%20Classification%20withInsect_examples.pdf
Write a comment
- Preethi Sharma May 14, 2018, 11:32 amHello, Allow me to show my gratitude bloggers. You guys are like unicorns. Never seen but always spreading magic. Your content is yummy. So satisfied. Very useful post !everyone should learn and use it during their learning path. Best Regards, Preethireply
Subscribe To Our Newsletter
Join our mailing list to receive the latest blogs and updates.