Working with Enterprise Search Relevancy Challenges

When enterprise searches are built from scratch, evaluation of the search quality remains key challenges of organizations implementing it. It always gives a feel of living in the darkness all the time. Such implementations demand enormous efforts and time. The chart below demonstrates a typical challenging situation in which organizations invest and work consistently on maturing the quality of searches over time, and yet remain far from satisfaction.
Diagram: Enterprise Search Relevancy
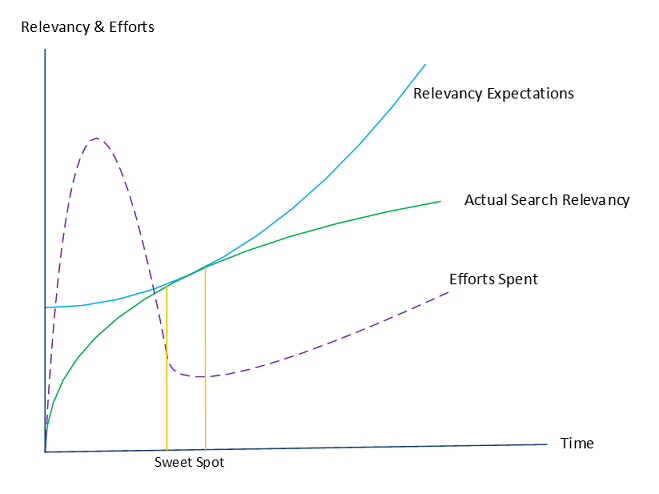
The amount of efforts and time spent on these tools rise exponentially with time; may reasons contribute to this factor. When the search relevancy expectations come close to the actual relevancy, organizations see the light at the end of the tunnel. However, it does not last long, due to many reasons, some of them are described below:
- Due to the continuous growth of information every day and increasing data participating in searches, tuning of the search application becomes a continuous and long-running activity
- Users become search aware, with increased usage, they expect improvements. Individuals often have a subjective assessment of relevancy and thus it gets challenging to build a single relevancy model for all
- An absence of good benchmarking strategy in the enterprise search landscape can prove to be a costly affair
- Lack of structured processes can prove to be a costly and time-consuming affair
In this blog, I intend to cover, how organizations can try defining the expectations, how they can measure the performance and quality against these benchmarks and how search relevancy problems can be optimized. We will start with defining the search expectation (Part 1):
Defining the Search expectations
To address the relevancy demands, organizations use various approaches. The challenge lies in reliability of these approaches given the subjective assessment of relevancy done by individuals and groups. Search relevancy should be evaluated against the information expected and not against the query, nor term matches. Unfortunately, most of the search tools like Apache Lucene/Solr, Elastic Search today, are based on keyword matches, which do not solve complex relevancy challenges. Hence we observe a huge demand for customizing searches.
To set the expectations for Enterprise Search, one needs to set the Relevancy Judgments or Relevancy Benchmarks, a process of collecting relevancy information from humans, that best represents predicted usage of the system. I will go over some of the approaches in this blog. One of the key aspects for determining quality of search relevancy is to evaluate its performance over sample queries. Many organizations consider TREC and Cranfield based listed public evaluations. They do serve a good purpose for refining the relevancy, however, that cannot be considered as the only valid criteria for Relevancy Benchmarking.
Pooling for Golden Datasets:
In this mechanism, relevancy benchmarks are captured over a subset of top k results from multiple domain experts. This can contribute and define the golden standards used while benchmarking search performance. An important aspect is to categorically identify, consolidate and define a single representation for unit. Since multiple experts evaluate the results, one mechanism is to measure their agreement levels, and take a decision on the given dataset. Below example shows two sample queries, with user (U1 and U2) agreements. DocId shows information in the document.
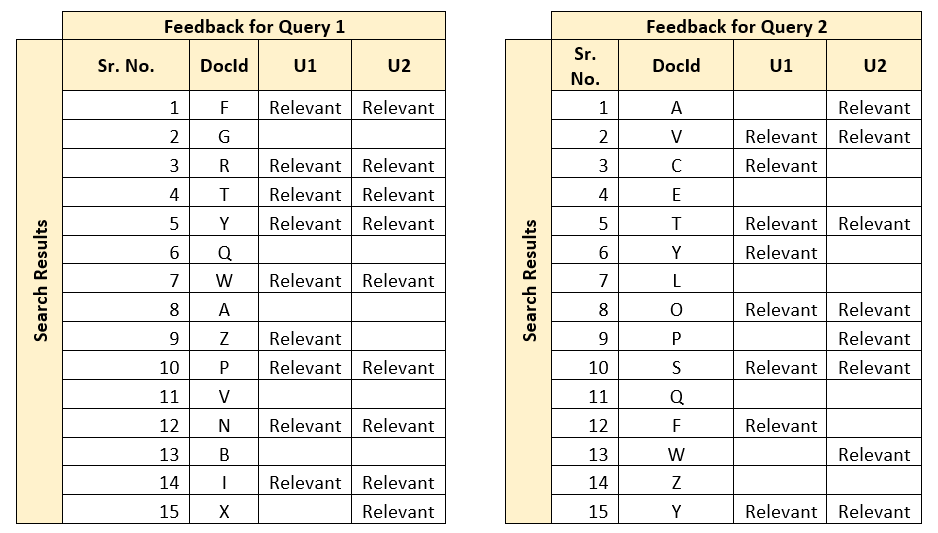
Once this information is captured, the agreement between these users can be found out through average, or a more robust statistical measure called Cohen’s Kappa Coefficient. To do that, first the relevant and irrelevant results need to be listed in a matrix format as shown below.
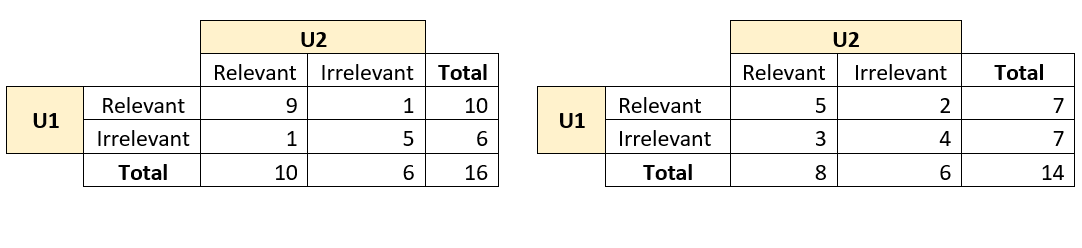
Now, you can identify the observed proportionate agreement (PA) as follows:

So, the PA calculated for Q1 and Q2 is:  Similarly, you can calculate the probability when both judges said yes to relevant or irrelevant documents and a probability of judge’s agreement over relevancy:
Similarly, you can calculate the probability when both judges said yes to relevant or irrelevant documents and a probability of judge’s agreement over relevancy: Using this formula, here are the calculations:
Using this formula, here are the calculations:  And finally, Cohen’s Kappa’s measure can be calculated with following:
And finally, Cohen’s Kappa’s measure can be calculated with following: 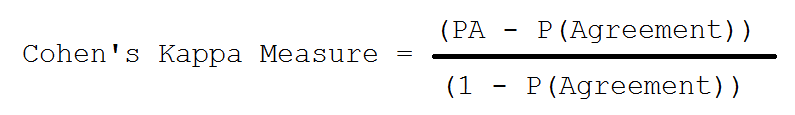 So, for our queries, the Kappa Measure is calculated as below:
So, for our queries, the Kappa Measure is calculated as below: 
As a rule of thumb, Kappa measure above 0.8 is considered as good agreement, 0.67 to 0.8 is considered to be fair agreement. Anything below 0.67, does not qualify for assessment. So, in the given example, Q1 Relevancy Benchmark qualifies to be part of the Golden dataset, whereas Q2 Relevancy Benchmark is not the right candidate for assessment. Next step is to formulate the golden dataset out of this, which can be simply done by identifying common relevant documents, as shown below (this is one of the measures):
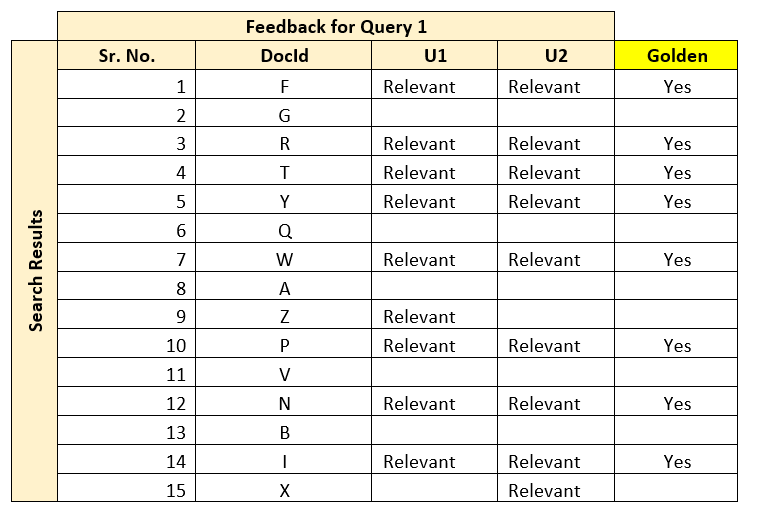
Once your golden dataset is formed over multiple iterations, it can be established as a Relevancy Benchmark for future search application tuning. Although this mechanism works well in general, some factors such as quality of users (whether they really represent the audience), their domain knowledge and expertise, etc. can impact the quality of the system.
In 3RDi Enterprise Search platform, the benchmarking system automatically handles all the complexities of managing and recording various pooling judgments from domain experts and allows them to create golden datasets. You can read more about it here: www.3rdisearch.com
In part 2, we will go over the other strategies to benchmark relevancy judgments and various relevancy measures.
Write a comment
Subscribe To Our Newsletter
Join our mailing list to receive the latest blogs and updates.